

Cloud TTS Hub admite el uso del lenguaje de marcado de síntesis de voz (SSML). SSML es un lenguaje de marcado basado en XML que le permite especificar muchos aspectos de cómo se sintetiza el texto en voz. Puede usarlo para afinar la pronunciación, la velocidad del habla, el tono de voz, el volumen y más.
SSML proporciona un lenguaje de marcado estándar, pero los proveedores individuales pueden tener diferencias en cómo se implementa. Debe utilizar el marcado compatible con el proveedor TTS en sus scripts TTS. Es posible que otras marcas de TTS no funcionen. Consulte la documentación de su proveedor de servicios TTS para obtener información sobre cualquier variación de SSML o requisitos específicos de ese proveedor.
Para usar SSML, la entrada de texto debe ser:
- XML válido
- SSML válido
- Contenido dentro de un conjunto de etiquetas <speak> </speak>
- Marcado con etiquetas que tienen cada una solo un atributo (esto incluye la etiqueta <speak>)
- Asignado a un objeto de datos dinámicos o una variable en una SNIPPET acción en su secuencia de comandos. El objeto o variable al que asigna el texto marcado debe usarse más adelante en su script en el lugar apropiado para pasarlo al proveedor de servicio TTS. Vea los ejemplos más adelante en esta sección. Al trabajar con SSML en fragmentos:
- Puede asignar texto SSML a objetos de datos dinámicos o variables regulares.
- Es necesario utilizar caracteres de escape en los valores de los objetos o variables.
- Puede utilizar comillas simples en lugar de comillas dobles en lugar de escapar las comillas dobles.
- Puede asignar un mensaje como un único bloque de texto a una variable, o puede dividirlo en múltiples variables.
Un script TTS que incluya SSML debería ser similar al siguiente ejemplo:
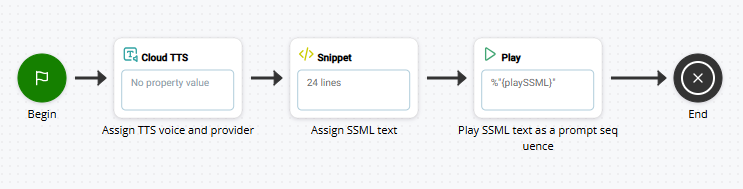
En este ejemplo, la acción CLOUD TTS define el proveedor TTS y la voz Cloud TTS Hub. La acción SNIPPET contiene el texto SSML marcado. El texto SSML se asigna a una variable que se pasa a la PLAY acción como una secuencia de solicitud. Si está utilizando esta opción con un agente virtual, deberá utilizar una VOICEBOT EXCHANGE acción en lugar de PLAY.
Ejemplo de un atributo por etiqueta en SSML
Este ejemplo muestra que el marcado SSML solo debe tener un atributo por etiqueta.
<speak xml:lang="en-US">
<voice name="en-US-JennyNeural"> Good morning Chris! </voice>
<voice name="en-US-ChristopherNeural"> Good morning to you too, Jenny! </voice>
</speak>
Ejemplo de múltiples oraciones con diferentes marcados en SSML
Este ejemplo muestra texto marcado con SSML que contiene varias oraciones entre
<speak xml:lang="en-US">
Here are <say-as interpret-as="characters">SSML</say-as> samples. I can pause <break time="3s"/>.
I can say cardinal numbers. This number is <say-as interpret-as="cardinal">1135</say-as>.
Or I can say ordinal numbers. You are <say-as interpret-as="ordinal">1135</say-as> in line.
I can even say numbers as digits. The digits are <say-as interpret-as="characters">1135</say-as>.
I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>.
</speak>
Ejemplo de un objeto de datos dinámicos con texto marcado en un fragmento de código
Este ejemplo muestra cómo asignar texto marcado con SSML a un objeto de datos dinámicos.
DYNAMIC promptSSML
ASSIGN promptSSML.prompt[1].textToSpeech = "<speak>The SSML should be read in the TTS voice selected in the CLOUD TTS action.\<speak\>";
ASSIGN promptSSMLJSON = "{promptSSML.asjson()}";Ejemplo de un mensaje asignado a una sola variable en un fragmento de código
Este ejemplo muestra cómo asignar texto marcado con SSML a una variable.
ASSIGN playSSML = "<speak xml:lang='en-US'>Here are the SSML samples. Here are <say-as interpret-as='characters'>SSML</say-as> samples. I can pause <BREAK time='3s'/>. I can say cardinal numbers. This number is <say-as interpret-as='cardinal'>1135</say-as> Or I can say ordinal numbers. You are <say-as interpret-as='ordinal>1135</say-as> IN line. I can even say numbers as digits. The digits are <say-as interpret-as='characters'>1135</say-as>. I can also substitute phrases, like the <sub alias='World Wide Web Consortium'>W3C</sub>. </speak>"Ejemplo de un mensaje distribuido en múltiples variables en código SNIPPET
Este ejemplo muestra el uso de múltiples variables para definir fragmentos del texto que desea que TTS diga. El valor de myText2 incluye el texto de myText. El texto de
ASSIGN myTime = "2:30pm"
ASSIGN myText = "<speak> Here are some examples of what CXone Mpower can do with SSML and cloud TTS. CXone can include a break <break time=3s/> in a spoken sentence as well as read back numbers in different ways."
ASSIGN myText2 = "{myText} for example, saying the number <say-as interpret-as=verbatim>12345</say-as> as individual digits or reading it as a cardinal number like this. <say-as interpret-as=cardinal>12345</say-as> ."
ASSIGN myText3 = "{myText2} CXone can also read back words as words or as individual characters <say-as interpret-as=characters>like this</say-as> ."
ASSIGN myText4 = "{myText3} CXone can also use SSML to slow down spoken sentences. <prosody rate=70%> to help people better understand something that's being said </prosody> "
ASSIGN myText5 = "{myText4} or speed them up <prosody rate=170%> where, for example, the fine print of an agreement can be read back in a short amount of time. </prosody> "
ASSIGN myText6 = "{myText5} Combining SSML and cloud TTS, CXone can also be used for many other things, like reading back time correctly like this. Currently, it's<say-as interpret-as=time format=hms24 detail=2>{myTime}</say-as></speak>"