

您可以觀看 影片,了解更多有關利用特別日子提高預測準確性的資訊。
在檢閱預測資料步驟時,您會看到所有選定技能的預測量和 AHT。 資料可能看起來不准確,而您希望看到正常值:
-
在某些區域看到 AHT 或數量異常低或為 0.00。
-
在週二和週三看到高峰數量,但歷史資料顯示週一達到了高峰,而下降趨勢一直持續到週五。
在這些情況下,請考慮變更歷史資料。
在歷史資料步驟中,尋找不太符合標準的日期。 例如,由於產品促銷,某一天的銷量可能過高。 但這不是一個標準的一天。 因此,對於某些技能,預測資料將顯示不准確的數量或 AHT。
為了提高預測量和 AHT 的準確性,將這些天定義為特別日子。 在特殊日子設定中,選擇從未來預測中排除這一天。 之後在預測資料步驟中將不會考慮這些天。
當全天的預測互動數量為 0 時,您將無法編輯數量。
透過按天 (1D) 檢視資料,您可以檢查全天的量是否為 0。 在日視圖中,您可以查看一天中每個間隔的資料。
若所有間隔的量都為 0,即表示無法對資料進行編輯。
要能夠編輯量,至少要變更一個間隔。
例如,1 月 25 日的預測互動量為 0。 您目前正在按月視圖 (1M) 尋找。 在這種情況下,您將無法進行編輯或批量編輯。
要編輯 25 日的互動量:
-
前往日視圖 (1D)。
-
至少編輯一個間隔。 假設,Jan 25 8:00 AM。 寫入 1或該間隔的所需值,而不是 0。
-
要對全天進行變更,請返回月視圖 (1M) 並編輯。
當您建立一個預測作業時,系統分兩個階段計算預測資料。 首先,根據所需的技能,在預測資料(預測的步驟 3)中產生資料。 第二,系統可以透過將工作量指派給多個排程單元來改善預測資料。 在定義人手編排參數後(步驟 4),會重新產生資料。 此次計算還考慮了可以處理互動的排程單元。 這最大程度確保了預測資料的準確性。 預測資料更新了人手編排(步驟 5)。
當您根據預測作業產生排程時,預測資料是基於步驟 5 中的資料。 最終的預測資料也顯示在 當日管理器 的預測欄中。
在預測過程中,(步驟 3)涉及生成原始預測,僅關注每個技能的數量和平均處理時間 (AHT),而不考慮客服專員。 從(步驟 3) 到(步驟 5),將發生模擬過程,將客服專員需求分配給處理預測技能的每個調度單元。 然後,這些要求將轉換回每個調度單元的每個技能的數量。
在(步驟 5)中,如螢幕截圖所示,我們可以觀察從上午 8:00 到 8:15 AM間隔內的數量和AHT,表示類比導致每個技能每個調度單元要處理的預期聯絡數量。
假設您於 2021 年 4 月啟用 ACD。 這時,歷史資料開始被收集。 之後,您在 2022 年 11 月啟動了WFM。 因為您已經收集了一年多的歷史資料,所以你應該能夠在生成預測時自動使用此資料。
然而,預測作業提示沒有歷史資料(在步驟 2)。 要解決此問題,您需要聯絡技術支援部門。 他們會將您收集的歷史資料匯入WFM。
系統正在按設計工作。 自動選擇功能會根據過去的資料自動選擇最佳預測模型。 在這種情況下,系統選擇了對給定數據最準確的模型。 儘管它在週四產生了一個峰值,但這是系統預期功能的一部分 - 它根據過去的結果選擇了似乎是最好的選擇。
結果的差異來自兩個模型如何處理數據:
-
自動選擇模型選擇了一種最適合過去數據的預測方法,但它選擇了每周模式(如星期四峰值)並將其帶入未來。
-
指數平滑 (ES) 模型可平滑數據,使其對這些星期四峰值不太敏感,併產生更穩定的預測。
這兩個模型給出的結果不同,因為它們旨在以不同的方式處理數據,並且每個模型都有其優勢,具體取決於數據的行為。
自動選擇模型正在執行其設計目的,它選擇它確定的模型將根據歷史數據提供最準確的預測。 但是,在極少數情況下,模型可能會發現未來不成立的異常模式,例如星期四峰值。 客戶可以使用自動選擇功能,但在某些特定情況下,他們可能需要手動選擇不同的模型(如指數平滑)以獲得更準確的預測。
考慮到客戶是高級許可證持有者,只要他們認為自動選擇的模型無法提供最佳結果,他們就可以選擇手動選擇預測模型。 這種靈活性使他們能夠根據自己的特定需求選擇最合適的型號。
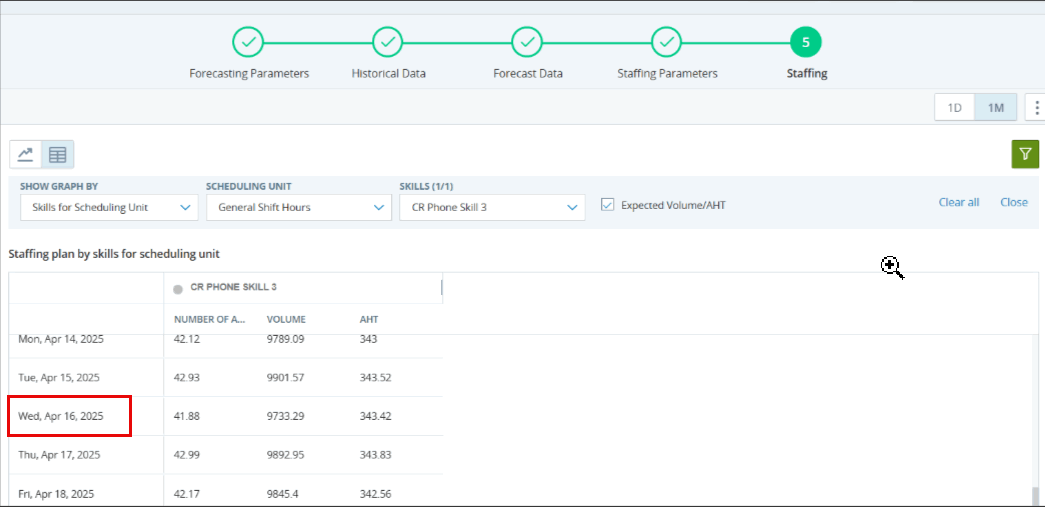
在下面作業的人員配備螢幕中,讓我們考慮 1 月 15 日技能「聯絡中心」的一個間隔,如下圖所示:
在上面的示例中,我們可以看到技能聯絡中心的交易量為 4.71,AHT 為 100.43。 這意味著在 900 秒(15 分鐘)間隔內,所有呼叫將由 AHT 為 100.43 的單個客服專員處理。 如果我們在計算中使用確切的數位,0.53 的人員配置要求是正確的,因為調度單元中有 67 名客服專員。
更改服務級別不會影響人員配備,因為我們有足夠的客服專員來處理呼叫。 當我們在人員編排生成期間查看調度單元中的聯絡中心配置時,我們發現共有 67 個客服專員可用於處理所選技能的呼叫。 因此,在生成人手編排需求時,如果每個間隔內有足夠的客服專員可用於處理預測的互動,則不考慮SLA ASA。
但是,如果在給定時間間隔內沒有足夠的客服專員來管理預測的呼叫,則會使用SLA ASA指標來確定滿足服務級別目標所需的客服專員數量。 此原則適用於此角色的所有間隔、技能和調度單元。 考慮到低數量和 AHT,以及足夠的可用客服專員數量,人員配備數量保持不變,因為有足夠的客服專員始終如一地滿足 100% SLA,因此ASA實際上計算為零。
根據歷史數據請求,我們驗證ACD技能是傳入還是傳出,WEM技能方向是傳入還是傳出。 如果它們不匹配,則歷史頁面上的消息指示方向不匹配。
錯誤訊息:
-
WEM 技能方向與 ACD 不符。 將這些 WEM 技能與 ACD:客戶支援 OB 結合起來。
可能的原因:
-
案例 1: WEM技能為傳入,但對其對應的ACD技能為傳出。
-
案例2: WEM和ACD技能均為傳出,但上傳的歷史數據標記為傳出。
-
案例3:WEM和ACD技能均為傳入,但由於上傳過程中傳出標誌設置為True,上傳的歷史數據標記為傳出。
-
案例 4: ACD技能被刪除並重新建立。 在這種情況下,WEM 技能和 ACD 技能之間的原始映射將丟失。
解決辦法:
-
確保上傳的歷史數據與ACD技能配置一致。 如果ACD技能定義為傳出,請在上傳過程中將 isOutboundFlag 設定為 True。 否則,如果ACD技能定義為傳入,請將isOutboundFlag設定為 False。
-
如果刪除並重新建立 ACD 技能,請將 WEM 技能重新配對到新建立的 ACD 技能。
-
如果 ACD 技能對應為呼入,但關聯的 WEM 技能的 指派到通道 設定為 撥號器,則必須刪除該 WEM 技能。 建立傳入類型的新WEM技能,並將其與相應的傳入ACD技能關聯。
-
從重新載入歷史資料WFM>預測>ACD歷史資料並確保至少有 13 週的歷史資料可用於準確預測。
在CXone Mpower WFM中,目標ASA(平均應答速度)是人手編排計算中使用的可選參數。
-
您可以將目標 ASA 定義為人手編排參數的一部分,但這不是強制性的。
-
如果您未定義目標 ASA,人手編排處理序仍會使用其他輸入 (例如服務水平目標) 來執行,以產生人手編排建議。
產生人手編排後,系統會執行模擬,模擬聯絡人如何在真實世界的 ACD 中到達、佇列和接聽。 根據此模擬,系統確定:
-
滿足定義目標(服務水平和/或 ASA)所需的客服專員數量。
-
客戶在計算出的人手編排中會遇到平均實際等待時間。
此實際等待時間將成為「即日」中顯示的預測ASA。
-
如果定義了目標 ASA,則預測的 ASA 將反映基於該目標的模擬結果。
-
如果未定義目標 ASA,則預測的 ASA 仍會作為基於服務水平的模擬的一部分自動計算。
無論是否配置了目標 ASA,「即日」一律會根據人手編排模擬顯示預測的 ASA。
當為同一 WEM 技能定義了多個服務目標(例如 服務水平、目標 ASA 和 最大佔用率)時,CXone Mpower WFM 會在人手編排模擬期間同時評估所有目標。
-
系統計算滿足每個單獨目標所需的客服專員數量。
-
然後,它從中選擇最高的人手編排需求。
範例:
-
服務水平目標需要 20 個客服專員
-
目標 ASA 需要 22 個客服專員
-
最大佔用率需要 18 個客服專員
-
最終人手編排需求 = 22 個客服專員(三個客服專員中的最多一個)
-
這種方法可確保人手編排建議滿足所有定義的服務目標,而不僅僅是一個目標。
當為同一 WEM 技能定義多個服務目標時,系統始終會根據最嚴格(最大)的要求進行人員配置,以確保滿足所有目標。
通常不建議為同一 WEM 技能定義多個服務目標。 每個目標都以不同的方式驅動人員配置,並可能引入相互衝突的限制。 例如:
-
服務水平和目標 ASA 旨在減少客戶等待時間。
-
最大佔用率限制客服專員利用率,這可能與 SL 和 ASA 的目標相衝突。
儘管如此,CXone Mpower WFM提供了在需要時支援此類場景的靈活性。 人手編排需求計算器評估多個選定的目標(無論是在人手編排設定檔中定義還是直接在預測工作中定義),並產生同時滿足這些目標的人手配置建議。
使用者有責任確保所選目標一致且不衝突。 啟用多個目標會增加人手編排解決方案的限制性,這可能導致人手過剩或排程不可行。
預測演算法使用不同的方法根據可用的歷史資料量計算 AHT:
如果可用的歷史資料少於 2 年:
-
該演算法使用移動加權平均來估計 AHT。
-
此計算在間隔層級執行,將權重套用至每個時間間隔內最近的資料點 (例如,15 分鐘或 30 分鐘區塊)。
如果有超過 2 年的歷史資料可用:
-
該演算法評估多個候選模型並選擇具有最低平均絕對誤差 (MAE) 的模型。
-
此模型選擇也應用於間隔層級,允許每個間隔根據其歷史 AHT 行為使用最佳擬合模型。
摘要:
-
< 2 年資料:移動加權平均→在間隔層級套用。
-
≥ 2 年資料: 使用 MAE 選擇的最佳擬合模型,→在間隔層級套用。