

U kunt een video bekijken voor meer informatie over het gebruik van speciale dagen om de nauwkeurigheid van prognoses te verbeteren.
Wanneer u de stap Prognosegegevens bekijkt, ziet u het voorspelde volume en de verwachte AHT voor alle geselecteerde skills. De gegevens lijken misschien vreemd:
-
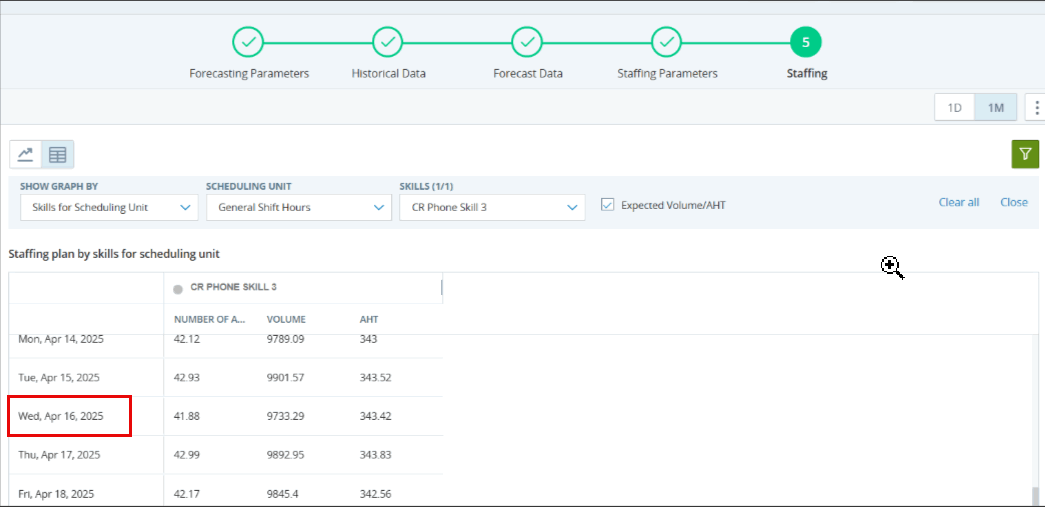
U ziet sommige gebieden waar de AHT of het volume ongewoon laag is (bijvoorbeeld 0).
-
U ziet volumepieken op dinsdag en woensdag, maar de historische gegevens tonen juist pieken op maandag en een aflopende trend tot vrijdag.
Overweeg in dergelijke gevallen om correcties aan te brengen in de historische gegevens.
Zoek in de stap Historische gegevens naar dagen die sterk afwijken van de norm. De volumes kunnen bijvoorbeeld veel te hoog zijn op een bepaalde dag vanwege een speciale productaanbieding. Dit is geen gewone dag. Daardoor zullen de prognosegegevens voor sommige skills afwijkende waarden voor het volume of de AHT laten zien.
Om de nauwkeurigheid van de voorspelde volumes en AHT-waarden te verbeteren, configureert u dergelijke dagen als Speciale dagen. Selecteer in de instellingen voor speciale dagen de optie Deze dag uitsluiten van toekomstige prognoses. Die dagen worden dan niet meer in aanmerking genomen bij de stap Prognosegegevens.
Wanneer het voorspelde interactievolume voor een hele dag 0 is, kunt u het volume niet bewerken.
U kunt controleren of het volume voor de hele dag 0 is door de data per dag (1D) te bekijken. In de dagweergave kunt u de data voor elk interval gedurende de dag bekijken.
Als het volume voor alle intervallen 0 is, is dat de reden dat u de data niet kunt bewerken.
Om het volume te kunnen bewerken, dient u minstens één interval te wijzigen.
Het voorspelde interactievolume op bijvoorbeeld 25 januari is 0. Momenteel bekijkt u de maandweergave (1M). In dit geval kunt u de data niet bewerken of bulksgewijs bewerken.
Het volume voor de 25ste bewerken:
-
Ga naar dagweergave (1D).
-
Bewerk minimaal één interval. Bijvoorbeeld Jan 25 8.00. Schrijf in plaats van 0, 1 of de gewenste waarde voor dat interval.
-
Om wijzigingen voor de hele dag door te voeren, gaat u terug naar de maandweergave (1M) en bewerkt u de data.
Wanneer u een prognosetaak maakt, berekent het systeem de prognosegegevens in twee fasen. De gegevens worden eerst gegenereerd in Prognosegegevens (stap 3 van prognose), gebaseerd op de vereiste skills. Ten tweede kan het systeem de prognosegegevens verbeteren de werklast te verdelen over meerdere planningseenheden. Na het definiëren van de bezettingsparameters (stap 4), worden de gegevens opnieuw gegenereerd. Deze keer wordt in de berekening ook rekening gehouden met de planningseenheden die de interacties kunnen afhandelen. Dit garandeert dat de prognosegegevens zo nauwkeurig mogelijk zijn. De prognosegegevens zijn bijgewerkt in bezetting (stap 5).
Wanneer u een planning genereert op basis van een prognosetaak, zijn de prognosegegevens gebaseerd op de gegevens in stap 5. De definitieve prognosegegevens worden ook weergegeven in de prognosekolommen in Intraday Manager.
Tijdens het prognoseproces (stap 3) wordt een ruwe prognose gegenereerd, waarbij de nadruk uitsluitend ligt op het volume en de gemiddelde afhandelingstijd (AHT) per vaardigheid, zonder rekening te houden met de agenten. Van (stap 3) tot (stap 5) vindt een simulatieproces plaats, waarbij de agentvereisten worden verdeeld over elke planningseenheid die de voorspelde vaardigheden verwerkt. Deze vereisten worden vervolgens terugvertaald naar volume per vaardigheid per planningseenheid.
In (stap 5), zoals weergegeven in de schermafbeelding, kunnen we het volume en de AHT voor het interval van 8:00 AM tot 8:15 AM observeren, wat het verwachte aantal contacten aangeeft dat per planningseenheid per vaardigheid moet worden afgehandeld als resultaat van de simulatie.
Stel dat u ACD op 20 april 2021 hebt geactiveerd. Vanaf dit punt worden historische gegevens verzameld. Vervolgens activeerde u WFM in november 2022. Aangezien u al ruim een jaar historische gegevens verzamelt, kunt u deze gegevens automatisch gebruiken bij het genereren van een prognose.
De prognosetaak meldt echter dat er geen historische gegevens zijn (in stap 2). U moet contact opnemen met Support om dit probleem op te lossen. De Support-medewerkers zullen de door u verzamelde historische gegevens importeren in WFM.
Het systeem werkt zoals het bedoeld is. De automatische selectiefunctie kiest automatisch het beste prognosemodel op basis van historische gegevens. In dit geval koos het systeem het model dat het meest nauwkeurig leek voor de gegeven gegevens. Hoewel er op donderdagen een piek was, is dit onderdeel van de beoogde functie van het systeem: het selecteerde wat de beste optie leek te zijn op basis van resultaten uit het verleden.
Het verschil in resultaten komt voort uit de manier waarop de twee modellen met de data omgaan:
-
Het autoselectiemodel koos een voorspellingsmethode die het beste werkte voor gegevens uit het verleden, maar pikte ook een wekelijks patroon op (zoals de piek op donderdag) en zette dit voort in de toekomst.
-
Het Exponential Smoothing (ES)-model egaliseert gegevens, waardoor ze minder gevoelig zijn voor de pieken van donderdag en een stabielere voorspelling opleveren.
Beide modellen leveren verschillende resultaten op, omdat ze zijn ontworpen om op verschillende manieren met de data om te gaan. Bovendien heeft elk model zijn sterke punten, afhankelijk van het gedrag van de data.
Het autoselectiemodel doet precies waarvoor het is bedoeld: het kiest het model dat volgens het model de meest nauwkeurige voorspelling oplevert op basis van historische gegevens. In zeldzame gevallen zoals deze kan het model echter ongebruikelijke patronen detecteren die in de toekomst niet meer gelden, zoals de piek op donderdag. De klant kan de functie voor automatisch selecteren gebruiken, maar in sommige specifieke situaties moet hij mogelijk handmatig een ander model kiezen (zoals exponentiële smoothing) om een nauwkeurigere prognose te krijgen.
Aangezien de klant een geavanceerde licentiehouder is, heeft hij de mogelijkheid om het prognosemodel handmatig te selecteren wanneer hij vindt dat het automatisch geselecteerde model niet de beste resultaten oplevert. Deze flexibiliteit biedt hen de mogelijkheid om het model te kiezen dat het beste bij hun specifieke behoeften past.
Laten we in het personeelsbestand voor de onderstaande functie een interval van 15 januari bekijken voor de vaardigheid 'Contactcenter', zoals gemarkeerd in de onderstaande afbeelding:
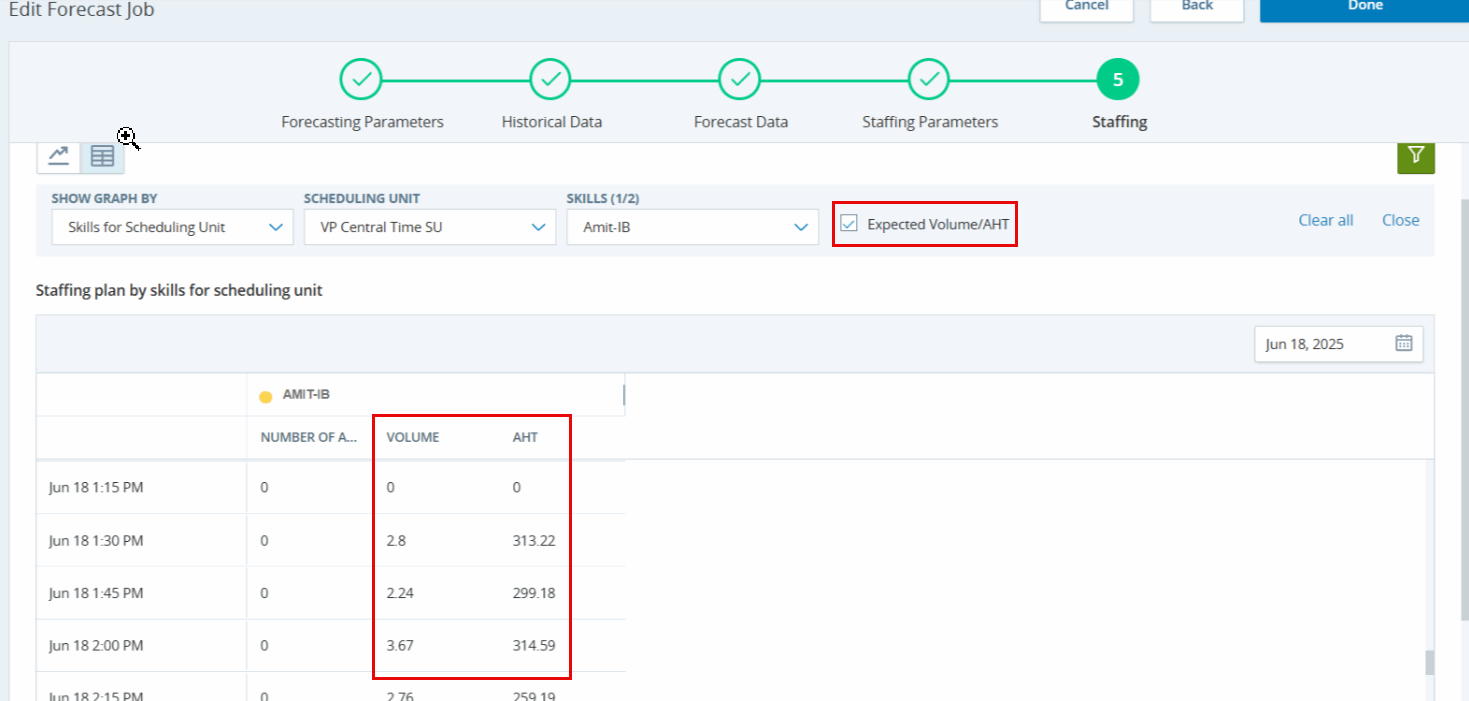
In het bovenstaande voorbeeld zien we dat het volume 4,71 is met een AHT van 100,43 voor de vaardigheid Contact Center. Dit betekent dat binnen een interval van 900 seconden (15 minuten) alle oproepen door één agent worden afgehandeld met een AHT van 100,43. Als we de exacte cijfers in onze berekeningen gebruiken, klopt de personeelsbehoefte van 0,53, aangezien er 67 agenten in de planningseenheid zitten.
Het wijzigen van het serviceniveau heeft geen gevolgen voor de personeelsbezetting, omdat we over voldoende medewerkers beschikken om de gesprekken af te handelen. Wanneer we kijken naar de configuratie van het Contact Center in de planningseenheid tijdens het genereren van personeel, zien we dat er in totaal 67 agenten beschikbaar zijn om gesprekken voor de geselecteerde vaardigheid af te handelen. Wanneer er personeelsvereisten worden gegenereerd en er voldoende agenten beschikbaar zijn om de voorspelde interacties in elk interval af te handelen, wordt SLA ASA niet in overweging genomen.
Als er echter niet voldoende agenten beschikbaar zijn om de voorspelde oproepen gedurende een bepaald interval af te handelen, wordt de SLA ASA-metriek gebruikt om het aantal agenten te bepalen dat nodig is om de serviceniveaudoelen te behalen. Dit principe is van toepassing op alle intervallen, vaardigheden en planningseenheden voor deze rol. Gezien het lage volume en de AHT en het voldoende aantal beschikbare agenten, blijven de personeelsbezettingscijfers ongewijzigd. Omdat er voldoende agenten zijn om consequent aan de 100% SLA te voldoen, wordt de ASA effectief berekend op nul.
Op basis van de historische gegevensaanvraag verifiëren we of de ACD-vaardigheid inkomend of uitgaand is en of de WEM-vaardigheidsrichting inkomend of uitgaand is. Als de richtingen niet overeenkomen, verschijnt er een bericht op de historische pagina dat aangeeft dat de richting niet overeenkomt.
Foutbericht:
-
De richting WEM-skills komt niet overeen met ACD. Stem deze WEM-vaardigheden af op ACD: Customer Support OB.
Mogelijke oorzaken:
-
Geval 1: De WEM-vaardigheid is binnenkomend, maar de ACD-vaardigheid die eraan is toegewezen, is uitgaand.
-
Geval 2: Zowel de WEM- als de ACD-vaardigheden zijn uitgaand, maar de geüploade historische gegevens zijn gemarkeerd als inkomend.
-
Geval 3: Zowel de WEM- als de ACD-vaardigheden zijn binnenkomend, maar de geüploade historische gegevens worden gemarkeerd als uitgaand omdat de vlag 'uitgaand' tijdens het uploaden is ingesteld op True.
-
Geval 4: De ACD-vaardigheid is verwijderd en opnieuw gemaakt. In dit geval gaat de oorspronkelijke koppeling tussen de WEM-vaardigheid en de ACD-vaardigheid verloren.
Oplossing:
-
Zorg ervoor dat historische gegevens worden geüpload in overeenstemming met de ACD-vaardigheidsconfiguratie. Als de ACD-vaardigheid als uitgaand is gedefinieerd, stelt u isOutboundFlag in op True tijdens het uploaden. Anders, als de ACD-vaardigheid is gedefinieerd als inbound, stelt u de isOutboundFlag in op False.
-
Als een ACD-vaardigheid is verwijderd en opnieuw is gemaakt, wijst u de WEM-vaardigheid opnieuw toe aan de nieuw gemaakte ACD-vaardigheid.
-
In gevallen waarin een ACD-vaardigheid is toegewezen als binnenkomend, maar de bijbehorende WEM-vaardigheid Toewijzen aan kanaal is ingesteld op Dialer, moet de WEM-vaardigheid worden verwijderd. Maak een nieuwe WEM-vaardigheid van het type 'inbound' en koppel deze aan de juiste inkomende ACD-vaardigheid.
-
Laad historische gegevens opnieuw vanuit WFM > Prognoses > ACD Historische gegevens en zorg ervoor dat er minimaal 13 weken aan historische gegevens beschikbaar zijn voor nauwkeurige prognoses.
In CXone Mpower WFM is Doel-ASA (Gemiddelde antwoordsnelheid) een optionele parameter die wordt gebruikt bij personeelsberekeningen.
-
U kunt een doel-ASA definiëren als onderdeel van uw personeelsbezettingsparameters, maar dit is niet verplicht.
-
Als u geen doel-ASA definieert, wordt het bezettingsproces nog steeds uitgevoerd met behulp van andere invoer, zoals het serviceleveldoel, om personeelsaanbevelingen te genereren.
Zodra de personeelsbezetting is gegenereerd, voert het systeem een simulatie uit die modelleert hoe contacten binnenkomen, in de wachtrij worden geplaatst en worden beantwoord in een echte ACD. Op basis van deze simulatie bepaalt het systeem:
-
Het aantal agenten dat nodig is om de vastgestelde doelen (Servicelevel en/of ASA) te behalen.
-
De gemiddelde werkelijke wachttijd die klanten zouden ervaren met de berekende personeelsbezetting.
Deze werkelijke wachttijd wordt de Voorspelde ASA die in Intraday wordt weergegeven.
-
Als er een doel-ASA is gedefinieerd, weerspiegelt de voorspelde ASA de simulatie-uitkomst op basis van dat doel.
-
Als er geen doel-ASA is gedefinieerd, wordt de voorspelde ASA nog steeds automatisch berekend als onderdeel van de op serviceniveau gebaseerde simulatie.
Ongeacht of er een doel-ASA is geconfigureerd, wordt in Intraday altijd een voorspelde ASA weergegeven op basis van de personeelsbezettingssimulatie.
Wanneer meerdere servicedoelen, zoals Servicelevel, Doel-ASA en Maximale bezetting, zijn gedefinieerd voor dezelfde WEM-skill, evalueert CXone Mpower WFM alle doelen gelijktijdig tijdens de bezettingssimulatie.
-
Het systeem berekent het aantal agenten dat nodig is om elk afzonderlijk doel te bereiken.
-
Vervolgens selecteert het de persoon met de hoogste personeelsbehoefte.
Bijvoorbeeld:
-
Serviceleveldoel vereist 20 agenten
-
Voor de doel-ASA zijn 22 agenten nodig
-
Voor maximale bezetting zijn 18 agenten vereist
-
Eindbezettingsvereiste = 22 agenten (het maximum van de drie)
-
Met deze aanpak zorgen we ervoor dat de aanbevelingen voor personeelsbezetting aan alle vastgestelde servicedoelen voldoen, en niet slechts aan één.
Wanneer er meerdere servicedoelen voor dezelfde WEM-skill zijn gedefinieerd, hanteert het systeem altijd de meest beperkende (grootste) vereiste om ervoor te zorgen dat aan alle doelen wordt voldaan.
Het wordt over het algemeen niet aanbevolen om meerdere servicedoelen voor dezelfde WEM-skill te definiëren. Elk doel heeft een andere invloed op de personeelsbezetting en kan conflicterende beperkingen met zich meebrengen. Voorbeeld:
-
Servicelevel en Target ASA zijn erop gericht de wachttijden voor klanten te verkorten.
-
Maximale bezetting beperkt de inzet van agenten, wat in strijd kan zijn met de doelen van SL en ASA.
Desondanks biedt CXone Mpower WFM de flexibiliteit om dergelijke scenario's te ondersteunen wanneer dat nodig is. De Bezettingsbehoeftecalculator evalueert meerdere geselecteerde doelen, ongeacht of deze zijn gedefinieerd in het bezettingsprofiel of rechtstreeks in de prognosetaak, en genereert bezettingsaanbevelingen die hieraan gelijktijdig voldoen.
Het is de verantwoordelijkheid van de gebruiker om ervoor te zorgen dat de geselecteerde doelen op één lijn liggen en niet met elkaar conflicteren. Het activeren van meerdere doelen verhoogt de restrictiviteit van de personeelsoplossing, wat kan resulteren in overbezetting of onhaalbare schema's.
Het voorspellingsalgoritme gebruikt verschillende methoden om AHT te berekenen op basis van de hoeveelheid beschikbare historische gegevens:
Als er minder dan 2 jaar aan historische gegevens beschikbaar zijn:
-
Het algoritme gebruikt een voortschrijdend gewogen gemiddelde om AHT te schatten.
-
Deze berekening wordt uitgevoerd op intervalniveau, waarbij gewichten worden toegepast op recente datapunten binnen elk tijdsinterval (bijvoorbeeld blokken van 15 minuten of 30 minuten).
Als er meer dan 2 jaar aan historische gegevens beschikbaar zijn:
-
Het algoritme evalueert meerdere kandidaatmodellen en selecteert het model met de laagste gemiddelde absolute fout (MAE).
-
Deze modelselectie wordt ook toegepast op intervalniveau, waardoor voor elk interval het best passende model kan worden gebruikt op basis van het historische AHT-gedrag.
Samenvatting:
-
< Gegevens over 2 jaar: Voortschrijdend gewogen gemiddelde → toegepast op intervalniveau.
-
≥ 2 jaar gegevens: Best passende model geselecteerd met MAE → toegepast op intervalniveau.