

予想精度を向上するためのスペシャルデイズの使用方法の詳細については、ビデオをご覧ください。
フォーキャストデータのステップを確認すると、選択したすべてのスキルの予測ボリュームとAHTの両方が表示されます。 通常の値が表示されることを期待しているのに、データは不正確に見える場合があります。
-
AHTまたはボリュームが異常に低いか0.00である一部の領域で見られます。
-
ボリュームのピークは火曜日と水曜日に表示されますが、履歴データは月曜日にピークを示し、金曜日まで減少傾向を示しています。
このような場合は、ヒストリカルデータに変更を加えることを検討してください。
ヒストリカルデータのステップで、標準に完全に準拠していない日を探します。 たとえば、商品のプロモーションが原因で、特定の日のボリュームが多すぎる場合があります。 今日は標準的な日ではありません。 このため、予測データには、一部のスキルの不正確なボリュームまたはAHTが表示されます。
予測ボリュームとAHTの精度を向上させるには、それらの日を次のように定義します特例日。 特別な日の設定で、この日を将来のフォーキャストから除外することを選択します。 これらの日は、フォーキャスティングデータステップでは考慮されません。
終日の予測インタラクションボリュームが0の場合、ボリュームを編集できません。
データを日別(1D)に表示することで、1日の通話ボリュームが0であることを確認できます。 日ビューでは、日中の各間隔のデータが表示されます。
すべての間隔の通話ボリュームが0の場合、データを編集できないのはそのためです。
通話ボリュームを編集できるようにするには、少なくとも1つの間隔を変更します。
たとえば、1月25日の予測インタラクション通話ボリュームは0です。 現在、月ビュー(1M)を見ています。 この場合、編集や一括編集はできません。
25日のボリュームを編集するには:
-
デイビュー(1D)に移動します。
-
少なくとも1つの間隔を編集します。 たとえば、1月25日午前8時00分とします。 0の代わりに、1またはその間隔の目的の値を記述します。
-
終日の変更を行うには、月ビュー(1M)に戻って編集します。
フォーキャストジョブを作成すると、システムはフォーキャストデータを2段階で計算します。 まず、必要なスキルに基づいて、フォーキャストデータでデータが生成されます(予測のステップ3)。 次に、システムは複数のスケジューリングユニットに仕事量を分散させることで、フォーキャストデータを改善することができます。 人員配置パラメーターを定義した後(ステップ4)、データが再生成されます。 その際、インタラクションを処理できるスケジューリングユニットも計算で考慮されます。 これにより、可能な限り正確なフォーキャストデータを得ることができます。 フォーキャストデータが人員配置で更新されます(ステップ5)。
フォーキャストジョブに基づいてスケジュールを作成する場合、そのフォーキャストデータはステップ5のデータに基づいています。 最終的なフォーキャストデータはイントラデイマネジャーのフォーキャストの列にも表示されます。
フォーキャストプロセス間(ステップ3)では、エージェントを考慮せずに、スキルごとのボリュームと平均処理時間(AHT)のみに焦点を当てて、生のフォーキャストを生成します。 (ステップ3)から(ステップ5)まで、シミュレーションプロセスが発生し、予測されたスキルを処理する各スケジューリングユニットにエージェント要件が分配されます。 これらの要件は、スケジューリング単位ごとのスキルごとのボリュームに変換されます。
(ステップ5)では、スクリーンショットに示すように、午前8:00から午前8:15までの間隔のボリュームとAHTを観察でき、シミュレーションの結果としてスキルごとにスケジューリング単位ごとに処理される予定のコンタクト数を示しています。
たとえば、2021年4月にACDをアクティブ化したとします。 この時、ヒストリカルデータが収集され始めます。 次いで、2022年11月にWFMがアクティブ化されました。 1年以上前から履歴データを収集しているため、フォーキャストを生成する際に自動的に使用することができるはずです。
しかしながら、フォーキャストジョブでは履歴データがないと知らされます(手順2で)。 これを解決するためには、サポートに連絡する必要があります。 収集した履歴データをWFMにインポートしてくれます。
システムは設計どおりに機能しています。 自動選択機能は、過去のデータに基づいて最適な予測モデルを自動的に選択します。 この場合、システムは、与えられたデータに対して最も正確と思われるモデルを選択しました。 木曜日にスパイクが発生しましたが、これはシステムの意図された機能の一部であり、過去の結果に基づいて最良のオプションと思われるものを選択しました。
結果の違いは、2 つのモデルがデータを処理する方法に由来します。
-
自動選択モデルは、過去のデータに最も適した予測方法を選択しましたが、週単位のパターン (木曜日のスパイクなど) を拾い上げ、それを未来に持ち越しました。
-
指数平滑化(ES)モデルはデータを平滑化するため、木曜日のスパイクに対する感度が低くなり、より安定した予測が生成されました。
どちらのモデルも、異なる方法でデータを処理するように設計されているため、異なる結果が得られており、各モデルにはデータの動作に応じて長所があります。
自動選択モデルは、設計されたとおりに動作し、履歴データに基づいて最も正確な予測を提供すると判断したモデルを選択します。 ただし、今回のようなまれなケースでは、木曜日の急上昇など、将来に当てはまらない異常なパターンをモデルが検出する可能性があります。 顧客は自動選択機能を使用できますが、特定の状況では、より正確な予測を取得するために、別のモデル (指数平滑化など) を手動で選択する必要がある場合があります。
お客様が上級ライセンス保有者であることを考慮すると、自動選択されたモデルが最良の結果を提供していないと感じた場合はいつでも、予測モデルを手動で選択することができます。 この柔軟性により、特定のニーズに最適なモデルを選択できます。
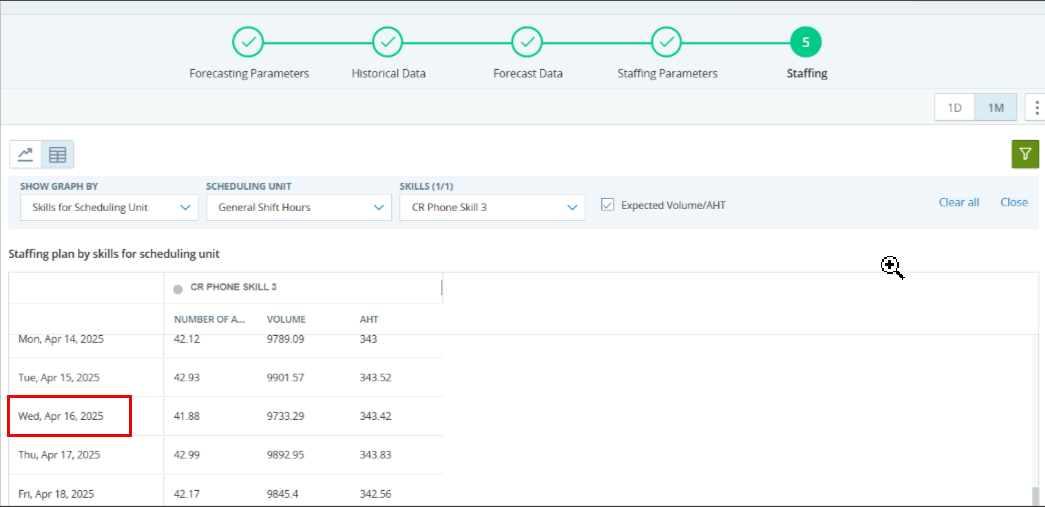
以下のジョブの人員配置画面で、下の画像で強調表示されているように、スキル「コンタクトセンター」の1月15日の1つの間隔を考えてみましょう。
上記の例では、スキルContact Centerのボリュームが4.71で、AHTが100.43であることがわかります。 つまり、900秒(15分)の間隔で、すべての通話がAHT100.43の1人のエージェントによって処理されます。 計算に正確な数値を使用すると、スケジューリングユニットには67人のエージェントがいるため、0.53人の人員配置要件は正しいです。
サービスレベルを変更しても、通話を処理するのに十分なエージェントがいるため、人員配置には影響しません。 人員配置の生成中にスケジューリングユニットのコンタクトセンター設定を見ると、選択したスキルの通話を処理できるエージェントが合計67人いることがわかります。 したがって、人員配置要件が生成されたときに、各間隔で予測されたインタラクションを処理するのに十分なエージェントがいる場合、SLA ASAは考慮されません。
ただし、特定の間隔で予測されたコールを管理するために使用できるエージェントが不足している場合は、SLA ASAメトリックを使用して、サービスレベル目標を達成するために必要なエージェントの数を決定します。 この原則は、この役割のすべてのインターバル、スキル、およびスケジューリングユニットに適用されます。 ボリュームと AHT、および使用可能なエージェントの適切な数を考慮すると、100% の SLA を一貫して満たすのに十分なエージェントがいるため、ASA は実質的にゼロとして計算されます。
ヒストリカルデータリクエストに基づいて、ACDスキルがインバウンドかアウトバウンドか、およびWEMスキルの方向がインバウンドかアウトバウンドかを確認します。 一致しない場合、履歴ページのメッセージは方向の不一致を示します。
エラーメッセージ:
-
WEMスキルの方向がACDと一致しません。 これらのWEMスキルをACDと連携させます:カスタマーサポートOB。
考えられる原因:
-
ケース1:WEMスキルはインバウンドですが、それにマッピングされたACDスキルはアウトバウンドです。
-
ケース2:WEMスキルとACDスキルの両方がアウトバウンドですが、アップロードされた履歴データはインバウンドとしてマークされます。
-
ケース3:WEMスキルとACDスキルの両方がインバウンドですが、アップロード中にアウトバウンドフラグがTrueに設定されているため、アップロードされた履歴データはアウトバウンドとしてマークされます。
-
ケース4:ACDスキルが削除され、再作成された。 この場合、WEMスキルとACDスキルの間の元のマッピングは失われます。
回避策:
-
履歴データがACDスキル設定に沿ってアップロードされていることを確認します。 ACDスキルがアウトバウンドとして定義されている場合は、アップロード中にisOutboundFlagをTrueに設定します。 それ以外の場合、ACDスキルがインバウンドとして定義されている場合は、isOutboundFlagをFalseに設定します。
-
ACDスキルを削除して再作成された場合は、WEMスキルを新しく作成したACDスキルに再マッピングします。
-
ACDスキルがインバウンドとしてマッピングされているが、関連するWEMスキルのチャネルに割り当てがダイヤラーに設定されている場合は、WEMスキルを削除する必要があります。 インバウンドタイプの新しいWEMスキルを作成し、適切なインバウンドACDスキルに関連付けます。
-
WFM > Forecasting > ACD ヒストリカルデータからヒストリカルデータを再読み込みし、正確な予測のために少なくとも13週間のヒストリカルデータが利用可能であることを確認します。
CXone Mpower WFMでは、Target ASA(平均回答速度)は、人員配置の計算で使用されるオプションのパラメーターです。
-
ターゲットASAは、人員配置パラメータの一部として定義できますが、必須ではありません。
-
ターゲット ASA を定義しない場合でも、人員配置プロセスは、サービスレベル ターゲットなどの他の入力を使用して実行され、人員配置の推奨事項が生成されます。
人員配置が生成されると、システムはシミュレーションを実行し、実際のACDでコンタクトがどのように到着し、キューに並び、応答されるかをモデル化します。 このシミュレーションに基づいて、システムは以下を決定します。
-
定義されたターゲット(サービスレベルおよび/またはASA)を満たすために必要なエージェントの数。
-
計算された人員配置で顧客が経験する平均実際の待ち時間。
この実際の待ち時間は、Intradayに表示される予測ASAになります。
-
ターゲット ASA が定義されている場合、予測 ASA にはその目標に基づくシミュレーション結果が反映されます。
-
ターゲット ASA が定義されていない場合でも、予測 ASA はサービスレベルベースのシミュレーションの一部として自動的に計算されます。
ターゲットASAが設定されているかどうかに関係なく、Intradayは常に人員配置シミュレーションに基づいて予測ASAを表示します。
同じWEMスキルに対してサービスレベル、ターゲットASA、最大稼働率などの複数のサービスターゲットが定義されている場合、CXone Mpower WFM人員配置シミュレーション中にすべてのターゲットを同時に評価します。
-
システムは、個々の目標を満たすために必要なエージェントの数を計算します。
-
次に、その中から最も高い人員配置要件を選択します。
以下に例を示します。
-
サービスレベル目標には20人のエージェントが必要
-
ターゲットASAには22人のエージェントが必要です
-
最大稼働率には18人のエージェントが必要
-
最終的な人員配置要件 = 22人のエージェント(3人のうち最大)
-
このアプローチにより、人員配置の推奨事項は、1 つだけでなく、定義されたすべてのサービス目標を確実に満たすことができます。
同じWEMスキルに対して複数のサービスターゲットが定義されている場合、システムは常に最も制限の厳しい(最大の)要件に合わせて人員を配置し、すべてのターゲットが満たされるようにします。
通常、同じWEMスキルに複数のサービスターゲットを定義することは推奨されません。 各ターゲットは人員配置を異なって推進し、相反する制約をもたらす可能性があります。 例えば、
-
サービスレベルとターゲットASAは、顧客の待ち時間を短縮することを目的としています。
-
最大稼働率はエージェントの使用率を制限し、SLおよびASAの目標と競合する可能性があります。
それにもかかわらず、CXone Mpower WFM は、必要に応じてこのようなシナリオをサポートする柔軟性を提供します。 人員配置要件計算ツールは、人員配置プロファイルで定義されているか、予測ジョブで直接定義されているかにかかわらず、選択された複数のターゲットを評価し、それらを満たす人員配置の推奨事項を同時に生成します。
選択したターゲットが整合し、競合しないようにするのはユーザーの責任です。 複数のターゲットをアクティブ化すると、人員配置ソリューションの制限が増し、人員過剰やスケジュールが実行不可能な状態になる可能性があります。
予測アルゴリズムは、利用可能な履歴データの量に基づいて、さまざまな方法を使用してAHTを計算します。
利用可能な履歴データが2年未満の場合:
-
このアルゴリズムは、移動加重平均を使用してAHTを推定します。
-
この計算は間隔レベルで実行され、各時間間隔 (たとえば、15 分または 30 分のブロック) 内の最近のデータ ポイントに重みを適用します。
2年以上のヒストリカルデータが利用可能な場合:
-
このアルゴリズムは複数の候補モデルを評価し、平均絶対誤差(MAE)が最も低いモデルを選択します。
-
このモデル選択は間隔レベルでも適用されるため、各間隔は、過去の AHT 動作に基づいて最適なモデルを使用できます。
概要:
-
<2年間のデータ:移動加重平均→間隔レベルで適用されます。
-
≥ 2年間のデータ: 間隔レベルで適用されたMAE→を使用して選択された最適モデル。